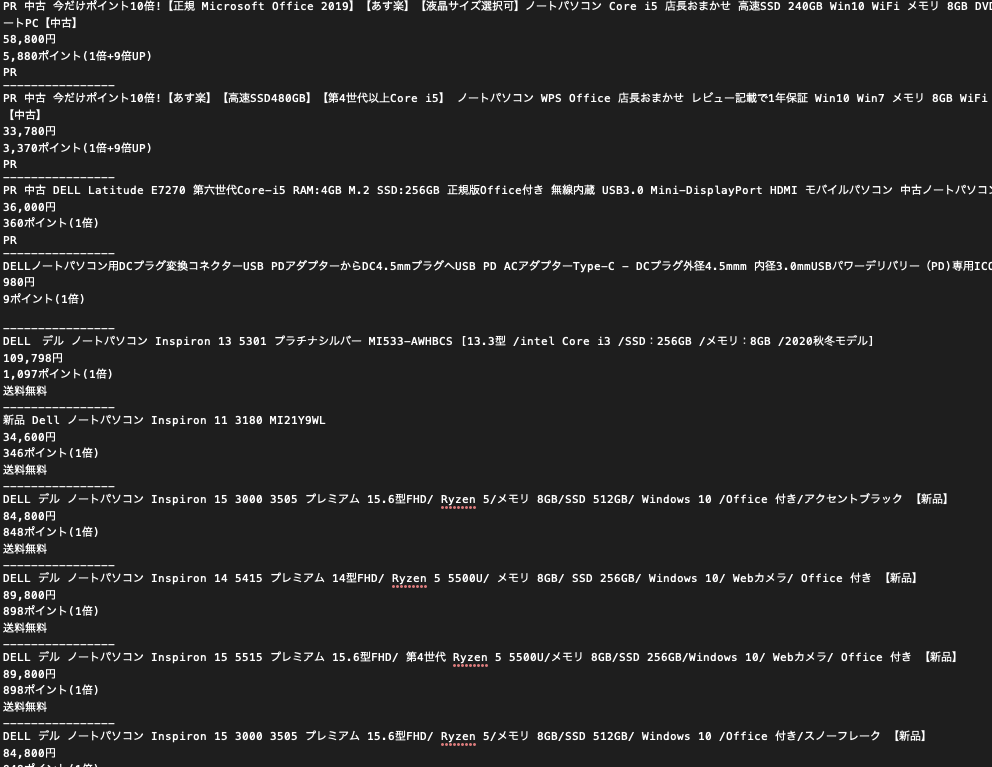
Pythonでメルカリの検索結果をスクレイピングしてみました。
コードはこちらのページを参照してます。
その他Googleで色々参照しながら作成しております。
準備
①seleniumのインストール (BeautifulSoupだけでは無理)
②ChromeDriverのDLと、コードと同階層への設置
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 指定のURLをブラウザで開く
# メルカリの検索一覧は取得できるのか?
# seleniumのインストールとchromedriverのdlで対応
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import os
from selenium.webdriver.chrome.options import Options
#-------------------------------------------------
## main ###
#-------------------------------------------------
if __name__=='__main__':
BASE_URL = 'https://www.mercari.com'
next_page_num = 2
# 100ランク取得
load_url = "https://www.mercari.com/jp/search/?keyword="
item = "ルースイソンブラ"
load_url = load_url + item
result_array = [['item_name','item_price','url']]
while True:
try:
# Chrome設定
options = Options()
options.add_argument('--headless')
# 対象URLにリクエスト
driver = webdriver.Chrome("./chromedriver", options=options)
driver.get(load_url)
time.sleep(5)
# 文字コードをUTF-8に変換し、html取得
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# tagとclassを指定して要素を取り出す
item_name = soup.find('div', class_='items-box-content clearfix').find_all('h3', class_='items-box-name font-2')
item_price = soup.find('div', class_='items-box-content clearfix').find_all('div',class_='items-box-price font-5')
item_url = soup.find('div', class_='items-box-content clearfix').find_all('a')
pager = soup.find('ul', class_='pager').find_all('a')
item_num = len(item_name)
for i in range(0, item_num):
result_array.append([item_name[i].text,
int(item_price[i].text.replace('¥', '').replace(',', '')),
BASE_URL + item_url[i].get('href')])
#結果表示
print(result_array)
for x in pager:
if x.text == str(next_page_num):
next_url = BASE_URL + x.get('href')
if next_url == '':
break
next_page_num += 1
load_url = next_url
next_url = ''
print('nextpagenum:' + str(next_page_num))
# デバッグなので1ページ目のみで抜ける。
if next_page_num == 3:
break
except Exception as e:
message = "[例外発生]" + os.path.basename(__file__) + "\n" + "type:{0}".format(type(e)) + "\n" + "args:{0}".format(
e.args)
print(message)
finally:
# 起動したChromeを閉じる
driver.close()
driver.quit()
一応取れました。絞り込みすれば価格調査とかで使えそうです。
定期チェックで最安値更新したらメール送るとかもできそうですね!